PEB Parsing & API Hashing
Technique de malware
Publié le
Introduction
Dans cet article nous allons voir le fonctionnement de deux techniques qui sont le parsing du PEB et l'API hashing, ensuite nous allons voir comment les déjouer. Le parsing du PEB et l'API hashing sont des techniques qui consistent à résoudre dynamiquement l'adresse d'une fonction, celles-ci sont utilisées dans des programmes malveillants qui ont pour objectif de déjouer l'analyse des programmes anti-virus mais aussi de ralentir les analystes de code malveillant puisque ces techniques rendent le code bien plus difficile à reverse.
D'un point de vue de l'analyse statique, en observant les librairies chargées lors de l'exécution nous remarquerons les fonctions utilisées par le programme. Dans la capture ci-dessous, nous sommes face à un programme n'utilisant pas la technique du parsing du PEB :
A présent, nous observons le même programme avec les fonctions VirtualAlloc, VirtualAllocEx et WriteProcessMemory qui sont manquantes car ici la technique du parsing du PEB est utilisée :
Nous remarquerons une différence au niveau des fonctions chargées dans la librairie Kernel32.dll, en effet les fonctions VirtualAlloc, VirtualAllocEx et WriteProcessMemory ne sont plus visibles de manière statique. Les programmes anti-virus et les analystes prêteront une attention particulière aux programmes dont la provenance n'est pas claire et pour lesquels l'enchaînement des fonctions permettant l'injection en mémoire est utilisé.
Pour rappel la fonction VirtualAlloc permet d’allouer une zone mémoire d'une taille bien définie durant son appel. Dans le cadre d'une injection de shellcode nous veillerons à spécifier la taille du shellcode dans la taille de la zone mémoire que nous voulons allouer. La fonction WriteProcessMemory se charge de l'écriture du shellcode (stocké dans une variable) dans la zone mémoire allouée précédemment par la fonction VirtualAlloc.
Explication du fonctionnement
Afin d'apporter un maximum de compréhension au fonctionnement du parsing du PEB, il est important de voir certains concepts comme la définition des structures TEB/PEB et le fonctionnement des programmes Windows sur la gestion des ressources.
Structure TEB / PEB
Le TEB (Thread Environment Block) et le PEB (Process Environment Block) sont des structures de données liées au système d'exploitation Windows. Ces structures permettent le bon fonctionnement d'un processus et d'un thread, nous y trouvons un ensemble d'informations. Par exemple dans le PEB nous retrouvons les paramètres d'exécution, les variables d'environnement, les handles, les modules chargés etc. Quant au TEB nous y trouvons des informations liées à un thread spécifique du processus en cours d'exécution comme son état, les informations de gestion des exceptions etc.
Le PEB est créé lorsque le processus démarre et est stocké dans la mémoire du processus. Le TEB est créé pour chaque thread en cours d'exécution et il est stocké dans la mémoire du processus auquel le thread appartient.

Ce qui nous intéresse ici ce sont les modules chargés en mémoire lors de l'exécution d'un processus. Par défaut un programme chargera au moins ces modules : NTDLL.DLL, KERNEL32.DLL et KERNELBASE.DLL.
Modules chargés en mémoire
L'objectif sera de parcourir l'ensemble des structures nous permettant de récupérer les modules chargés en mémoire. Pour cela nous allons devoir accéder à la structure du TEB en premier lieu ce qui nous permettra de récupérer l'adresse du PEB. Par la suite nous accéderons à la structure du PEB afin de retrouver l'adresse du Ldr qui est un pointeur sur la structure _PEB_LDR_DATA pour accéder à l'adresse InInitializationOrderModuleList. Cette adresse pointe sur la structure _LIST_ENTRY qui apparaît sous la forme d'une double liste chaînée nous permettant de naviguer entre les modules vers l'avant ou vers l'arrière. Les données récupérées dans cette structure seront utilisées pour y afficher les informations complètes du module à travers la structure _LDR_DATA_TABLE_ENTRY.
Voici un schéma résumant le chemin à parcourir :

Afin d'apporter plus de clarté à l'explication ci-dessus, nous allons répéter les étapes pas à pas en prenant le programme notepad.exe comme exemple. Dans un premier temps nous allons ouvrir WinDBG puis nous allons nous attacher au processus notepad.exe afin de lancer notre première commande dt _TEB @$teb où la variable @$teb contient l'adresse du TEB :
Ensuite nous afficherons la structure du PEB en spécifiant son adresse (nous aurions pu directement utiliser la commande dt _PEB @$peb mais nous garderons cette logique pour l'appliquer dans le code) :
Nous récupérerons ensuite la structure _PEB_LDR_DATA qui contiendra la structure InInitializationOrderModuleList à offset + 0x1c :

La structure InInitializationOrderModuleList est une double liste chaînée qui lie tous les modules entre eux. Cette méthode de structuration de la donnée permet d'ordonner le chargement des modules. Voici à quoi ressemble l'état de la structure pour le premier module :

Si nous souhaitons connaître le module chargé il suffit d'appeler la structure _LDR_DATA_TABLE_ENTRY avec le bon alignement (pour ça il faudra simplement retirer 0x10) :
Si nous souhaitons connaître le deuxième module chargé nous procéderons ainsi :
Lorsque nous voulons récupérer le paramètre contenant le nom du module, il faut savoir que lorsque nous affichons la structure _LDR_DATA_TABLE_ENTRY nous arrivons au niveau du paramètre InInitializationOrderModuleList, c'est donc pour cela qu'il y a un problème d'alignement et que nous devons retirer 0x10 pour afficher la structure avec des données correctes. Voici notre position avant de corriger l'alignement :
- Le nom du module contenu dans le paramètre BaseDllName qui se trouve à [ADDR + 0x20]
- Son adresse de base contenue dans DllBase qui se trouve à [ADDR + 0x08]
Concernant le paramètre BaseDllName, la valeur que nous récupérerions correspond à celle située à l'offset 0x30 de la structure _LDR_DATA_TABLE_ENTRY soit à _LDR_DATA_TABLE_ENTRY+0x30. Sur l'image ci-dessus nous sommes induits en erreur par le paramètre BaseDllName nous indiquant sa valeur à la position _LDR_DATA_TABLE_ENTRY+0x2c mais si nous regardons la structure dans laquelle il pointe nous allons nous rendre compte qu'il faudra ajouter +0x4 :

Afin de vérifier voici la valeur contenue à [ADDR + 0x20] :

Nous pouvons définir la méthode de structuration des données comme le schéma ci-dessous :
Après avoir affiché les éléments de la structure _LDR_DATA_TABLE_ENTRY, nous sommes en mesure de récupérer les symboles d'un module à l'aide d'un premier paramètre présent qui se trouve être DllBase. Ce que nous devons retenir c'est que chaque élément d'un module se trouve à un offset bien particulier de celui-ci, nous pouvons parler ici d'adresse virtuelle relative. La structuration des données contenues dans les modules est la même pour tous.
L'élément qui permet de distinguer les modules est la valeur de DllBase. L'addition de DllBase et l'adresse virtuelle relative donnera l'adresse virtuelle réelle de la donnée souhaitée.
Voici le schéma des structures nous permettant d'identifier les symbols chargés dans les modules :
Pour exemple, prenons le module KERNEL32.DLL. Nous allons procéder étape par étape depuis WinDBG. Commençons par récupérer la signature à offset 0x3c :
Ensuite nous récupérons la valeur contenue à cette adresse pour l'additionner avec la valeur de DllBase et un offset de 0x78 pour aller à l'adresse virtuelle relative (RVA) pointant sur la structure IMAGE_EXPORT_DIRECTORY. Pour accéder à la structure pour le cas du module KERNEL32.DLL il suffira d'y ajouter la valeur de DllBase pour obtenir la véritable adresse virtuelle (VA) :

Maintenant que nous avons l'adresse virtuelle de la table des exports nous allons pouvoir récupérer deux valeurs qui sont :
- Le nombre de symboles
- Le pointeur vers l'adresse relative de la liste des symboles
Rendu WinDBG :

Pour obtenir les adresses contenant le nom des symboles nous ferons le calcul suivant : [ VA liste symboles + nb symbol-i * 4 ] + DllBase :

Enfin, l'obtention des adresses des symboles se fera en deux temps, pour commencer nous devons refaire un tour dans la structure IMAGE_EXPORT_DIRECTORY où nous pointerons sur le paramètre Ordinal Table RVA qui est un paramètre nécessaire qui agira comme un index pour obtenir l'adresse des symboles :
Toujours dans la structure IMAGE_EXPORT_DIRECTORY nous pointerons sur le paramètre Address Table RVA qui à son tour pointera sur EXPORT Address Table qui contient les adresses des symboles :
Voici la relation entre EXPORT Name Pointer Table, EXPORT Ordinal Table et EXPORT Address Table sous forme d'un schéma :
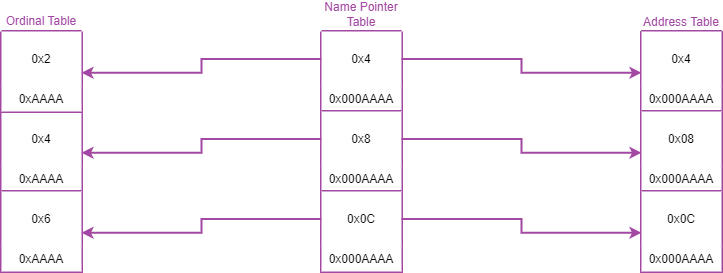
Voici la formule adaptée à cette relation :
eax = eax + ((ecx - 0x1) * 0x4) // EXPORT Name Pointer Table
eax = eax + ((ecx - 0x1) * 0x2) // EXPORT Ordinal Table
edx = edx + (eax * 0x4) // EXPORT Address TableCorrespondance des hash
Nous savons à présent comment sont chargés les modules dans la mémoire d'un processus et comment récupérer les adresses des symboles qui nous intéressent. L'objectif de l'API hashing est de pouvoir charger des modules et leurs symboles dynamiquement de manière furtive donc il n'est pas intéressant d'inscrire des chaînes de caractères dans notre programme afin de tester des égalités. Cependant, dans un premier temps nous pouvons calculer le hash d'une chaîne de caractères, en l'occurrence le symbole souhaité. Dans un second temps nous calculerons le hash de tous les noms de symbole qui seront énumérés. Il s'agit là de la technique de l'API hashing.
Voici la fonction nous permettant de calculer le hash du symbole en cours (le registre esi contient le nom du symbole en cours de traitement, le registre ebx contient la valeur de DllBase et le registre edi contient la structure IMAGE_EXPORT_DIRECTORY) :
hashing:
lodsb ; Load the next byte from esi into al
test al, al ; Check for NULL terminator
jz compare ; Jump into the compare function once the string is read
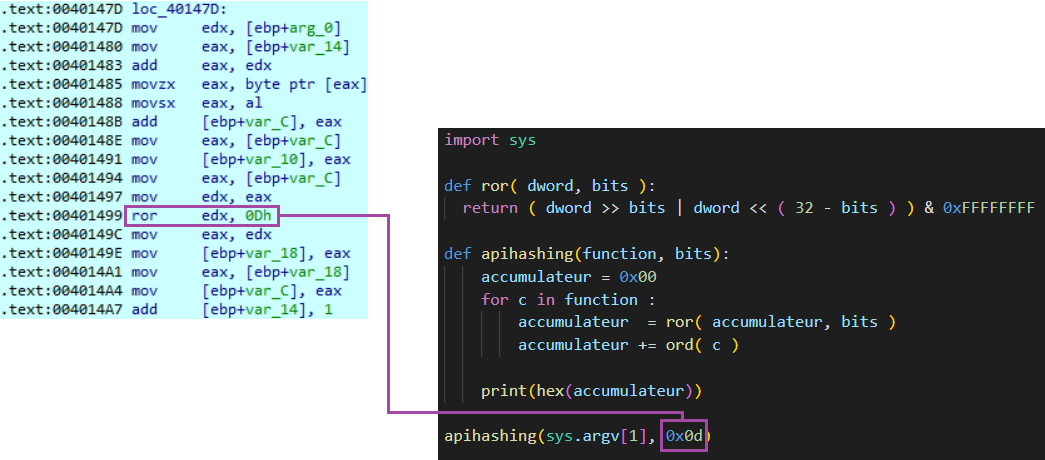
ror edx, 0x0d ; Rotate edx 13 bits to the right
add edx, eax ; Add the new byte into the accumulator
jmp hashing ; Next iteration
compare:
cmp edx, [esp+0x24] ; Compare the calculated hash with the hash provided
jnz enumeration ; If it doesn't match go back to enumeration function
mov edx, [edi+0x24] ; AddressOfNameOrdinals RVA
add edx, ebx ; AddressOfNameOrdinals VMA
mov cx, [edx+2*ecx] ; Extrapolate the function's ordinal
mov edx, [edi+0x1c] ; AddressOfFunctions RVA
add edx, ebx ; AddressOfFunctions VMA
mov eax, [edx+4*ecx] ; Get the function RVA
add eax, ebx ; Get the function VMA
ret
Cette approche nous permettra de référencer uniquement les hash des fonctions que nous souhaitons invoquer. Examinons de plus près un programme malveillant utilisant cette technique.
Dans sa première fonction, le programme appellera deux fois la fonction sub_4014C0, en lui passant respectivement les valeurs hexadécimales 0x48317727 et 0x13B56D18 comme arguments. Nous pouvons supposer que ces valeurs hexadécimales font référence aux hash des fonctions demandées.
Voici le code de la première fonction du programme :

Dans la fonction sub_4014C0 nous reconnaîtrons l'énumération de symbole et un appel à la fonction sub_401460, il s'agira là de la fonction permettant le hashage de la chaîne de caractères placée en argument :
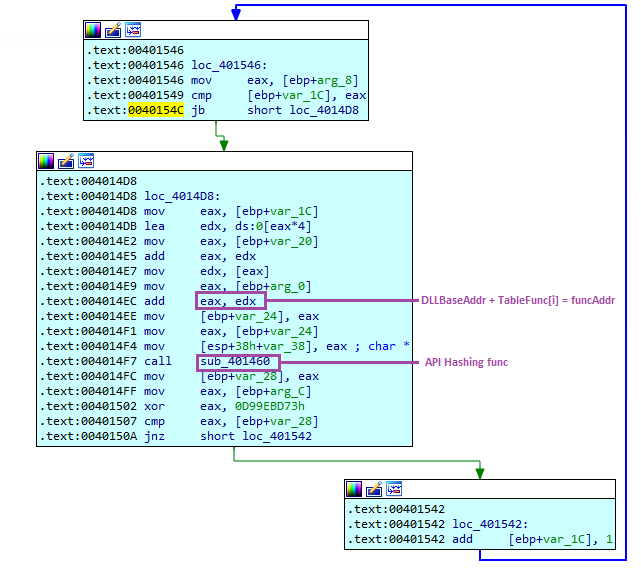
À ce stade, nous pourrions naïvement supposer qu'il suffit d'accéder à la fonction de hachage et de récupérer l'octet utilisé pour l'opération ROR. Il est noté ici que la valeur 0x0d est utilisée pour cette opération. Cependant, après avoir modifié notre programme de hachage en Python pour tester tous les symboles de plusieurs modules, nous n'arrivons toujours pas à retrouver la fonction qui tente d'être chargée :
De retour dans la fonction précédente nous remarquerons une opération XOR avec la valeur hexadécimale 0xd99ebd73 suivie d'un jump conditionnel :

L'opération XOR est effectuée avec la valeur de retour de la fonction de hashage et si le résultat est égal à la valeur hexadécimale envoyée en argument à l'appel de cette fonction alors le programme ira récupérer l'adresse de la fonction. Nous pouvons définir le pseudocode suivant :
for ( DWORD i = 0; i < (DWORD)NumberOfNames; i++ ) {
unsigned int hash = apihashing(pFunctionName);
if ( hash == ( hash ^ 0xd99ebd73 ) ) {
PEsignature = BaseAddr + 0x3c;
IMAGE_EXPORT_DIRECTORY_RVA = BaseAddr + PEsignature + 0x78;
IMAGE_EXPORT_DIRECTORY_VMA = BaseAddr + IMAGE_EXPORT_DIRECTORY_RVA;
OrdinalTable_RVA = IMAGE_EXPORT_DIRECTORY_VMA + 0x24;
OrdinalTable_VMA = BaseAddr + OrdinalTable_RVA;
index = OrdinalTable_VMA + 2 * i;
FunctionTable_RVA = IMAGE_EXPORT_DIRECTORY_VMA + 0x1c;
FunctionTable_VMA = BaseAddr + FunctionTable_RVA;
FunctionAddr_RVA = FunctionTable_VMA + 4 * index;
FunctionAddr_VMA = BaseAddr + FunctionAddr_RVA;
}
}
La deuxième valeur hexadécimale agit comme une clé. Nous remarquerons que cette clé est renseignée en dur cela veut dire qu'elle est aussi présente lors de son deuxième appel dans la première fonction du malware. Nous pouvons donc supposer que :
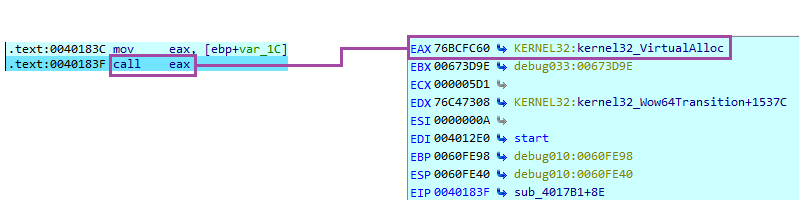
[Première valeur hexadécimale] ^ [clé hexadécimale 0xd99ebd73] = réel hash. Après vérification, nous remarquerons que la première fonction qui tente d'être appelée est VirtualAlloc :

Nous pouvons vérifier simplement en laissant tourner le programme jusqu'à la prochaine instruction call eax :
Enfin, voici en résumé les étapes à suivre pour déjouer cette technique :
- - Repérer le moment où le PEB est récupéré via le segment fs à offset +0x30.
- - Repérer le moment où la table des ordinaux offset +0x24 et la table des adresses offset +0x1c sont utilisées puisqu'il s'agit du moment où la fonction souhaitée est trouvée.
- - Repérer la prochaine instruction call [REGISTRE].
Conclusion
Le PEB Parsing et l'API hashing sont des techniques souvent utilisées par les programmes malveillants mais leur application n'est pas aussi simple que démontrée dans cet article. De plus, dans certains programmes nous pourrions observer la présence de mécanismes d'anti-debugging et d'anti-VM associés à ces techniques. Il est donc essentiel d'analyser le programme pas à pas afin d'en comprendre le sens.